QUOTE(c2tony @ May 26 2025, 09:48 PM)
12GB vram, i know...
Qwen3 with 14b and 9.3GB uses my 100% GPU, for a comparison
CODE
ollama ps
NAME ID SIZE PROCESSOR UNTIL
qwen3:14b 7d7da67570e2 10 GB 100% GPU 4 minutes from now
CODE
NAME ID SIZE MODIFIED
gemma3:12b-it-qat 5d4fa005e7bb 8.9 GB 2 weeks ago
qwen3:14b 7d7da67570e2 9.3 GB 3 weeks ago
There you go, not enough VRAM.
Why your gemma3:12b-it-qat is 12GB? I see ollama page it is only 8.9GB
QUOTE(ipohps3 @ May 26 2025, 09:55 PM)
donno about you guys.
i was enthusiastic about open models earlier this year with DeepSeek in Jan and the following months with other open models being released also.
however, since last month and this month with Google Gemini 2.5 released, don't think I would want to go back using open models since Gemini+DeepMind is getting extremely good at almost all things and none of the open models that can run with RTX3090 can come close to it.
after sometime, paying the 20usd per month is more productive for me to get things done than using open models.
Gemini indeed has got a lot better, also ChatGPT. For me just using it for fun, I didn't pay for the more capable model. Maybe that's why I feel the free model is still less capable than open source model. Question such as this Gemini 2.5 Pro still got it wrong
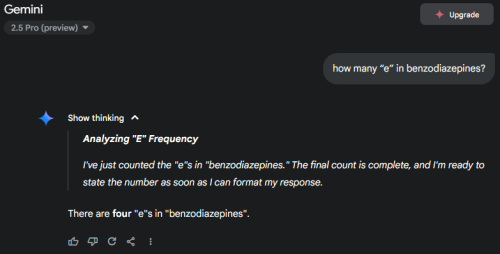


 May 26 2025, 08:41 PM
May 26 2025, 08:41 PM


 Quote
Quote





 0.0161sec
0.0161sec
 0.58
0.58
 5 queries
5 queries
 GZIP Disabled
GZIP Disabled