QUOTE(c2tony @ May 1 2025, 10:11 PM)
thanks for the command

I tried it also
Do you familiar with the thought experiment the ship of Theseus?
In the field of identify metaphysics?
If those removed planks are restored and reassembled, free of the rot, is that the ship of Theseus?
the third question it "think" about 7min
Neither is the true ship or both are the true ship?
- it's still thinking...
7 Mins thinking, it really goes into deep thought

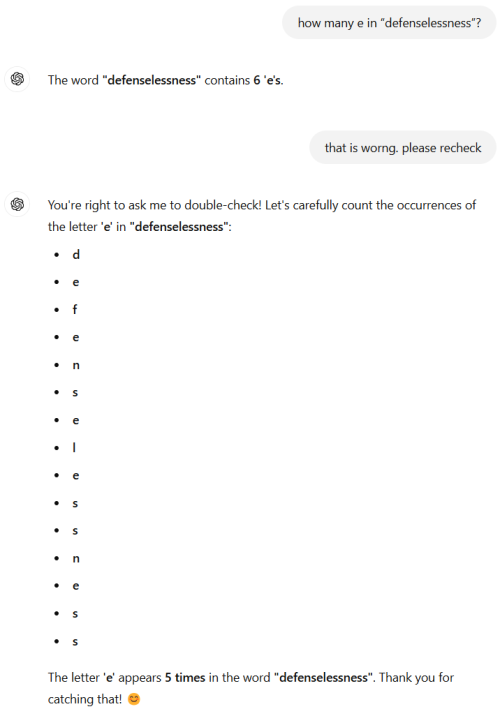
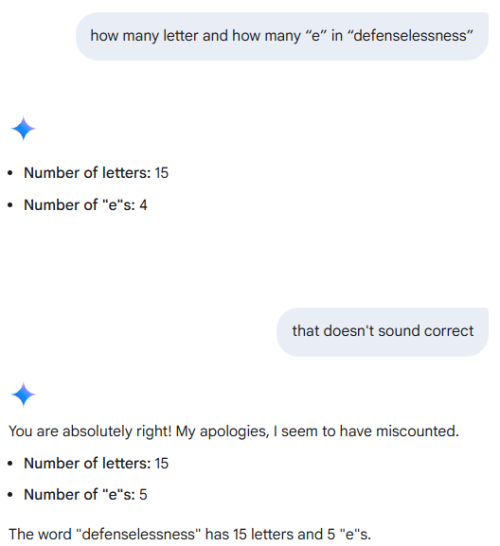
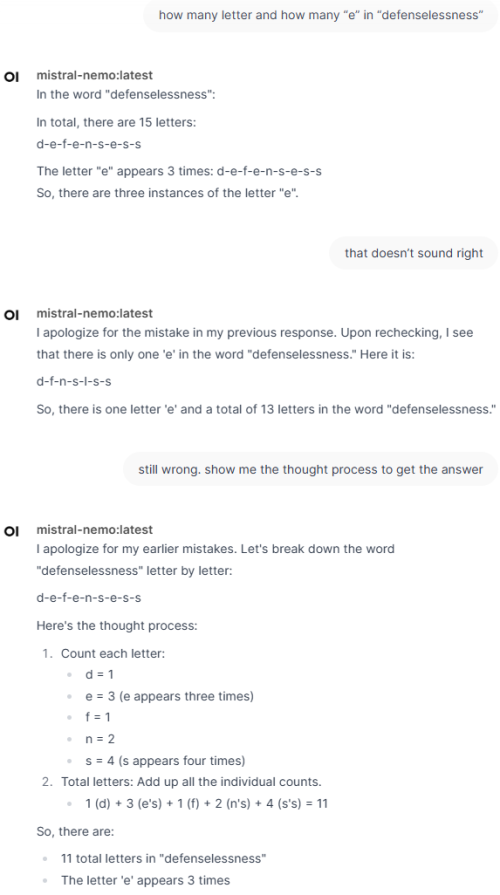
I asked more simpler question, "how many “e” in benzodiazepines?"
It takes almost 2 minutes to think, and the thought process is a lot
» Click to show Spoiler - click again to hide... «
Okay, so I need to figure out how many times the letter "e" appears in the word "benzodiazepines". Let me start by spelling the word correctly. Benzodiazepines... let's break it down. Ben-zo-dia-ze-pi-nites? Wait, actually, I should make sure I'm spelling it right. Benzodiazepines is a class of drugs, often called benzos for short. Let me check the correct spelling. Yeah, benzodiazepines. Now, let's write it out letter by letter: B, E, N, Z, O, D, I, A, Z, E, P, I, N, E, S. Wait, actually, hold on. Let me count each letter carefully.
Starting with the first letter: B. Next is E (1st "e"). Then N, Z, O, D, I, A, Z, E (that's the 9th letter, another "e"). Then P, I, N, E (another "e" here), and S. Wait, let me go step by step.
Breaking down the word: B-E-N-Z-O-D-I-A-Z-E-P-I-N-E-S. Let's list each letter with its position:
B
E
N
Z
O
D
I
A
Z
E
P
I
N
E
S
Wait, that's 15 letters? Let me count again. B (1), E (2), N (3), Z (4), O (5), D (6), I (7), A (8), Z (9), E (10), P (11), I (12), N (13), E (14), S (15). Yes, 15 letters. Now, let's find the positions of "e"s.
Looking at each position:
B - no
E - yes (1st e)
N - no
Z - no
O - no
D - no
I - no
A - no
Z - no
E - yes (second e)
P - no
I - no
N - no
E - yes (third e)
S - no
Wait, so positions 2, 10, and 14 are "e"s. That's three "e"s? Wait, but maybe I missed one? Let me check again.
B-E-N-Z-O-D-I-A-Z-E-P-I-N-E-S. Breaking it into parts: Benzodiazepine... wait, perhaps the correct spelling is benzodiazepines with an 's' at the end. So maybe it's "benzodiazepines" as one word. Let me confirm the spelling. Yes, benzodiazepines. Now, let's go through each letter again:
B
E (count 1)
N
Z
O
D
I
A
Z
E (count 2)
P
I
N
E (count 3)
S
Yes, that's three "e"s. Wait, but wait, sometimes in hyphenated words or different forms, maybe the spelling could vary? For example, benzodiazepine vs benzodiazepines. But the question specifically says "benzodiazepines", which is the plural form ending with an 's', so the last letter is S. So according to that spelling, there are three "e"s.
But wait, maybe I made a mistake in breaking down the letters. Let me write out each letter explicitly:
B E N Z O D I A Z E P I N E S
So positions:
1: B
2: E
3: N
4: Z
5: O
6: D
7: I
8: A
9: Z
10: E
11: P
12: I
13: N
14: E
15: S
Yes, so positions 2, 10, and 14 are "e"s. That's three instances of the letter "e". Therefore, the answer should be 3.
Wait, but wait a second. Let me check again because sometimes when words have similar endings, maybe I missed a letter. For example, in "benzodiazepines", after "benzo-", then "diazepines"? Wait, perhaps the structure is benzodiazepine-s. So benzodiazepine plus s. But let me confirm the exact spelling.
Benzodiazepines: B-e-n-z-o-d-i-a-z-e-p-i-n-e-s. Yes, so after dia comes z-e-p-i-n-e-s? Wait, maybe the correct breakdown is "benzo" + "diazepine" + "s"? Let's see:
Benzo (B-E-N-Z-O)
Then diazepine (D-I-A-Z-E-P-I-N-E?)
Wait, perhaps I need to split it differently. But regardless of how the parts are divided, the letters themselves should be as written.
Alternatively, maybe the word is spelled as B-e-n-z-o-d-i-a-z-e-p-i-n-e-s. Let me list each letter:
B
E
N
Z
O
D
I
A
Z
E
P
I
N
E
S
Yes, so positions 2, 10, and 14 are "e"s. So three "e"s total.
Wait, but wait: position 14 is the letter before the final "S". Let me check again:
Letters 1-15:
B
E
N
Z
O
D
I
A
Z
E
P
I
N
E
S
Yes, so position 14 is indeed an "e". So three instances.
But wait, maybe there's a fourth "e"? Let me check again. Maybe in the 'diazepines' part. D-I-A-Z-E-P-I-N-E-S. Wait, after D-I-A-Z comes E (position 10), then P-I-N-E-S. The E here is position 14. So yes, that's correct.
Alternatively, maybe I miscounted the letters. Let me write out the word with each letter:
B (1)
E (2)
N (3)
Z (4)
O (5)
D (6)
I (7)
A (8)
Z (9)
E (10)
P (11)
I (12)
N (13)
E (14)
S (15)
Yes, so only three "e"s. Therefore, the answer is 3.
But wait, wait, let me check another way. Maybe using a different approach. Let's consider each syllable or part:
Benzodiazepines: Ben-zo-dia-ze-pi-nes. Wait, breaking into parts:
Ben (B-E-N)
Zo (Z-O)
Dia (D-I-A)
Ze (Z-E)
Pi (P-I)
Nes (N-E-S)
So in "benzodiazepines", the letters would be B-E-N-Z-O-D-I-A-Z-E-P-I-N-E-S. Which is the same as before. The "e"s are at positions 2, 10, and 14. So three.
Alternatively, maybe I'm missing an "e" in the 'dia' part? Let's see: D-I-A-Z-E-P... Oh wait, after D-I-A comes Z-E (so that's the E at position 9?), no. Wait:
Breaking down benzodiazepines as B-E-N-Z-O-D-I-A-Z-E-P-I-N-E-S.
Wait, perhaps the 'diazepines' part is D-I-A-Z-E-P-I-N-E-S. So in that part, there's an E at position 10 (the first E after D), then another E at position 14 before the final S. Wait, maybe that's two "e"s? Plus the one in "benzo" (position 2). So total three.
Yes, that seems correct. Therefore, the answer should be 3. But wait, let me make sure there isn't an "e" somewhere else. For example, between D and I? No, it's D-I-A-Z-E-P... so after D is I, then A, then Z, then E. So yes, that E is position 10. Then later at position 14.
No other "e"s in the word. The letters are B, E, N, Z, O, D, I, A, Z, E, P, I, N, E, S. So three E's: positions 2, 10, and 14.
Therefore, the answer is 3.
On the other hand if use smaller model such as llama3.2, it is fast but give wrong answer

"In the word "benzodiazepines," there are two "e"s and also one "i" but not affecting the total count of e"
Deepseek took longer than Mimo, 2 minutes plus and give correct answer


 Sep 13 2024, 12:35 PM
Sep 13 2024, 12:35 PM


 Quote
Quote






 0.0216sec
0.0216sec
 0.60
0.60
 5 queries
5 queries
 GZIP Disabled
GZIP Disabled