QUOTE(ipohps3 @ Jun 5 2025, 03:37 PM)
what is it qat quantization?
Instead of compressing the photo into smaller jpeg, we tell the artist to paint with fewer color instead.
it = instruction tuned not that the model are fluent in Italian language 😁
quantization:
Convertion of finished painting to a desired jpeg compression
qat (Quantization-Aware Training):
Qat is like instead of compressing the photo into smaller jpeg, we tell the artist to paint with fewer color instead
hmm...... is that why Gemma3 occupy so much more memory but it's not that slow
btw
IT-QAT refers to instruction-tuned Quantization-Aware Training (QAT) models, specifically in the Gemma 3 series. These models are optimized using QAT to maintain high quality while significantly reducing memory requirements, making them more efficient for deployment on consumer-grade GPUs.
For example:
- Gemma 3 27B IT-QAT → Reduced from 54GB to 14.1GB
- Gemma 3 12B IT-QAT → Reduced from 24GB to 6.6GB
- Gemma 3 4B IT-QAT → Reduced from 8GB to 2.6GB
- Gemma 3 1B IT-QAT → Reduced from 2GB to 0.5GB
These models are designed to preserve similar quality as half-precision models (BF16) while using less memory, making them ideal for running locally on devices with limited resources.
This post has been edited by c2tony: Jun 7 2025, 08:50 AM 

 Aug 21 2024, 07:57 PM
Aug 21 2024, 07:57 PM

 Quote
Quote





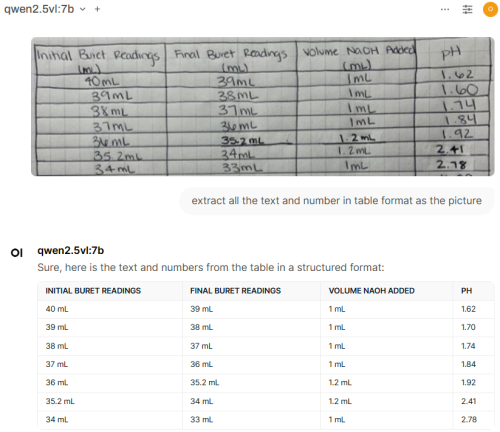
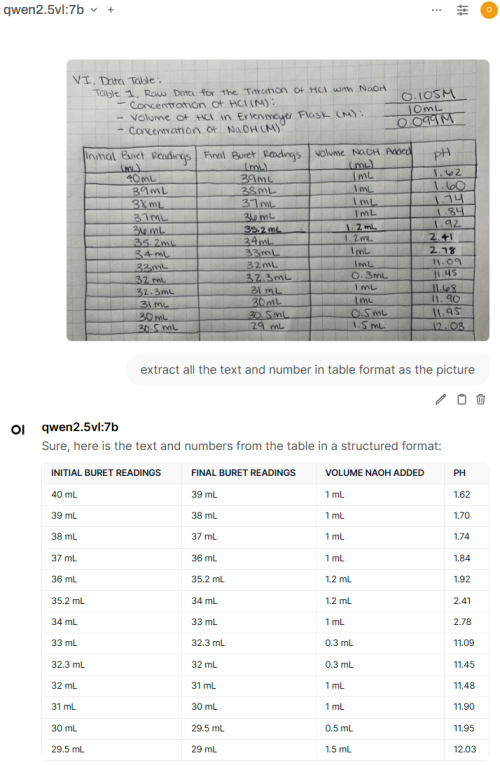




 still better than single gpu card with the same price
still better than single gpu card with the same price  0.0178sec
0.0178sec
 1.11
1.11
 6 queries
6 queries
 GZIP Disabled
GZIP Disabled