

This post has been edited by ipohps3: Jan 28 2025, 01:22 PM
Full DeepSeek R1 At Home 🥳🥳🥳
Full DeepSeek R1 At Home 🥳🥳🥳
|
|
 Jan 28 2025, 01:21 PM, updated 11 months ago Jan 28 2025, 01:21 PM, updated 11 months ago
Show posts by this member only | Post
#1
|

Senior Member
1,974 posts Joined: Dec 2011 |
Penamer liked this post
|
|
|
|
|
|
Jan 28 2025, 01:22 PM
Show posts by this member only | Post
#2
|
|
Senior Member
1,974 posts Joined: Dec 2011 |
moooore memory...
|
|
|
Jan 28 2025, 01:22 PM
Show posts by this member only | Post
#3
|

Senior Member
975 posts Joined: Aug 2007 From: Lokap Polis |
slow la. better just use proper graphic card instead.
|
|
|
Jan 28 2025, 01:25 PM
Show posts by this member only | Post
#4
|
|
Senior Member
1,974 posts Joined: Dec 2011 |
QUOTE(zerorating @ Jan 28 2025, 01:22 PM) slow la. better just use proper graphic card instead. wonder if it is using the NPU, GPU or CPU in the M4 Mac Mini. if NPU, no need dedicated GPU also can. also, inside the M4 Mac Mini got GPU too. main thing is memory. |
|
|
Jan 28 2025, 01:26 PM
Show posts by this member only | Post
#5
|

Junior Member
651 posts Joined: Mar 2009 |
i have 3 gpu on floor
can i setup r1 ? |
|
|
Jan 28 2025, 01:29 PM
Show posts by this member only | Post
#6
|
|
Senior Member
975 posts Joined: Aug 2007 From: Lokap Polis |
QUOTE(ipohps3 @ Jan 28 2025, 01:25 PM) wonder if it is using the NPU, GPU or CPU in the M4 Mac Mini. if NPU, no need dedicated GPU also can. also, inside the M4 Mac Mini got GPU too. main thing is memory. most likely GPU. they will need extra work to get NPU doing the hard lifting. also NPU is optimized for performance/watt, it wont be faster than GPU with AI accelerator. |
|
|
|
|
|
Jan 28 2025, 02:06 PM
Show posts by this member only | IPv6 | Post
#7
|

Junior Member
140 posts Joined: Jul 2007 From: Puchong |
Who need that kind of setup??
Graphic designers? |
|
|
Jan 28 2025, 02:09 PM
Show posts by this member only | Post
#8
|
|
Junior Member
98 posts Joined: Jan 2023 |
Sampah punya AI pun ada hype.
|
|
|
Jan 28 2025, 02:10 PM
Show posts by this member only | Post
#9
|

Junior Member
62 posts Joined: Apr 2018 |
dis 1 is localised, no internet
i download ady the android version not bad the chain of tot n reasoning all listed 4 u to see |
|
|
Jan 28 2025, 02:14 PM
|
|
Senior Member
1,974 posts Joined: Dec 2011 |
QUOTE(ihm11 @ Jan 28 2025, 02:10 PM) dis 1 is localised, no internet can register new account?i download ady the android version not bad the chain of tot n reasoning all listed 4 u to see also only possible to run without internet if open-source. |
|
|
Jan 28 2025, 02:19 PM
|

Elite
15,694 posts Joined: Mar 2008 |
QUOTE(ipohps3 @ Jan 28 2025, 02:14 PM) can register new account? Note that the open source model you can run the distilled version, not the full one they hosted in cloud. You need crazy amount of fast GPUs to make the full version workable. Have fun enjoy heating you room. also only possible to run without internet if open-source.  This post has been edited by kingkingyyk: Jan 28 2025, 02:22 PM |
|
|
Jan 28 2025, 02:21 PM
|

Senior Member
3,833 posts Joined: Oct 2006 From: Shah Alam |
better just pay chatgpt plus. only usd20 per month. lol
|
|
|
Jan 28 2025, 02:22 PM
Show posts by this member only | IPv6 | Post
#13
|

Junior Member
0 posts Joined: Apr 2022 |
I am running a RM50million business company with just my M1 MacBook Air.
|
|
|
|
|
|
Jan 28 2025, 02:23 PM
|

Junior Member
112 posts Joined: Aug 2006 |
QUOTE(kingkingyyk @ Jan 28 2025, 02:19 PM) Note that the open source model you can run the distilled version, not the full one they hosted in cloud. You need crazy amount of fast GPUs to make the full version workable. Have fun enjoy heating you room. what's the difference, preciousss? |
|
|
Jan 28 2025, 02:23 PM
|

Elite
10,672 posts Joined: Jul 2005 From: shah alam - skudai - shah alam |
What does it do? What's the difference between running the one online?
|
|
|
Jan 28 2025, 02:23 PM
|
|
Elite
15,694 posts Joined: Mar 2008 |
QUOTE(kurtkob78 @ Jan 28 2025, 02:21 PM) better just pay chatgpt plus. only usd20 per month. lol If you already have some big VRAM GPUs, open source LLM lets you utilize the computing power at no cost (well, you could argue there is TNB bill).  |
|
|
Jan 28 2025, 02:26 PM
|
|
Junior Member
473 posts Joined: Sep 2019 |
QUOTE(kingkingyyk @ Jan 28 2025, 02:19 PM) Note that the open source model you can run the distilled version, not the full one they hosted in cloud. You need crazy amount of fast GPUs to make the full version workable. Have fun enjoy heating you room. Bruh. The full model is also open source:https://github.com/deepseek-ai/DeepSeek-R1 ollama too: https://ollama.com/library/deepseek-r1 Edit: lol you edited This post has been edited by hellothere131495: Jan 28 2025, 02:27 PM |
|
|
Jan 28 2025, 02:29 PM
|
|
Junior Member
239 posts Joined: May 2022 |
Obviously you don't know AI at all
If DeepSeek is sampah All AI related tech giants won't cirit-birit in a row QUOTE(zoozul @ Jan 28 2025, 02:09 PM) Sampah punya AI pun ada hype. |
|
|
Jan 28 2025, 02:30 PM
Show posts by this member only | IPv6 | Post
#19
|
|
Junior Member
830 posts Joined: Mar 2010 |
running the 1.5bn q4_k_m locally on my NAS
slow af, but it worked so I dont have to work with o1 free-limit |
|
|
Jan 28 2025, 02:30 PM
|
|
Junior Member
473 posts Joined: Sep 2019 |
QUOTE(azarimy @ Jan 28 2025, 02:23 PM) What does it do? What's the difference between running the one online? Same. The same model. Just that you probably won't have the chance to run the online one. It's full 32 bit and 671B parameters. What you can run is the distilled (and quantized) version, like the qwen and llama3.1 8b one that has been distilled to respond like the original deepseekr1 |
|
|
Jan 28 2025, 02:31 PM
|
|
Senior Member
3,833 posts Joined: Oct 2006 From: Shah Alam |
QUOTE(kingkingyyk @ Jan 28 2025, 02:23 PM) If you already have some big VRAM GPUs, open source LLM lets you utilize the computing power at no cost (well, you could argue there is TNB bill). 16GB VRAM sufficient to run o1 level intelligence ? |
|
|
Jan 28 2025, 02:31 PM
Show posts by this member only | IPv6 | Post
#22
|

Senior Member
4,894 posts Joined: May 2008 |
ok.....so world peace achieved?
|
|
|
Jan 28 2025, 02:32 PM
|
|
Junior Member
473 posts Joined: Sep 2019 |
QUOTE(jmas @ Jan 28 2025, 02:30 PM) running the 1.5bn q4_k_m locally on my NAS 1.5b 4bit is slow? what spec are you using? btw, you probably still need the o1. 1.5b 4 bit is a shit model that hallucinates a lot.slow af, but it worked so I dont have to work with o1 free-limit |
|
|
Jan 28 2025, 02:32 PM
|
|
Junior Member
239 posts Joined: May 2022 |
The speed of China Tech is really terrifying
Luckily such power is in the hand of highly civilised nation China is the future of humanity |
|
|
Jan 28 2025, 02:32 PM
|
|
Elite
15,694 posts Joined: Mar 2008 |
QUOTE(emefbiemef @ Jan 28 2025, 02:23 PM) what's the difference, preciousss? https://github.com/deepseek-ai/DeepSeek-R1/...s/benchmark.jpgHere is the comparison. The full 671b models need over 400GB of memory to run, which is out of reach for most people. Distillation transfers the knowledge to smaller model (i.e. feeding the QA chain), but smaller model has way fewer parameters so they won't be generating result so well. The list of distilled models: - DeepSeek-R1-Distill-Qwen-1.5B - DeepSeek-R1-Distill-Qwen-7B - DeepSeek-R1-Distill-Llama-8B - DeepSeek-R1-Distill-Qwen-14B - DeepSeek-R1-Distill-Qwen-32B - DeepSeek-R1-Distill-Llama-70B 32B can let you run on RTX5090 nicely with context (the QA chain is involved to generate further response), but how many of us can justify buying that 5 digits GPU + heavy TNB bill just to run this? This post has been edited by kingkingyyk: Jan 28 2025, 02:33 PM |
|
|
Jan 28 2025, 02:33 PM
|
|
Junior Member
239 posts Joined: May 2022 |
At this rate Full fledged offline AI robot is possible Penamer liked this post
|
|
|
Jan 28 2025, 02:33 PM
|
|
Junior Member
473 posts Joined: Sep 2019 |
QUOTE(kurtkob78 @ Jan 28 2025, 02:31 PM) 16GB VRAM sufficient to run o1 level intelligence ? ah lol. 16GB vram is a kid toy that can only run 4-bit quantized small models.o1 is a big model. you probably need around 400GB vram to run it (in 4 bit probably). To run the full 32 bit idk need how much. lazy to calculate. |
|
|
Jan 28 2025, 02:35 PM
|
|
Junior Member
473 posts Joined: Sep 2019 |
QUOTE(JonSpark @ Jan 28 2025, 02:31 PM) ok.....so world peace achieved? No. a war has just started? see the news? china deepseek is getting attacked, probably by US |
|
|
Jan 28 2025, 02:36 PM
|
|
Elite
15,694 posts Joined: Mar 2008 |
QUOTE(kurtkob78 @ Jan 28 2025, 02:31 PM) 16GB VRAM sufficient to run o1 level intelligence ? https://ollama.com/Try the 12b/14b models yourself.  The general performance is quite acceptable, but due to the amount of parameters, won't work well in depth. 7900XTX is the best price-performance card for such purpose. Gives you 24GB VRAM and just cost you 5K. |
|
|
Jan 28 2025, 02:37 PM
|
|
Junior Member
830 posts Joined: Mar 2010 |
QUOTE(hellothere131495 @ Jan 28 2025, 02:32 PM) 1.5b 4bit is slow? what spec are you using? btw, you probably still need the o1. 1.5b 4 bit is a shit model that hallucinates a lot. N100 processor je, no GPU, its truenas machineoriginally installed ollama just for fun now considering putting it on my desktop |
|
|
Jan 28 2025, 02:50 PM
Show posts by this member only | IPv6 | Post
#31
|
|
Senior Member
4,894 posts Joined: May 2008 |
QUOTE(hellothere131495 @ Jan 28 2025, 02:35 PM) No. a war has just started? see the news? china deepseek is getting attacked, probably by US 8 M4 units and no world piss? Best it can do is run Crysis on max? |
|
|
Jan 28 2025, 03:01 PM
Show posts by this member only | IPv6 | Post
#32
|

Junior Member
382 posts Joined: Dec 2008 From: /k/ |
So it's better than Nvidia?
|
|
|
Jan 28 2025, 03:01 PM
|
|
Junior Member
90 posts Joined: May 2022 |
QUOTE(GagalLand @ Jan 28 2025, 02:33 PM) At this rate I think it is still a long way to go before we can get AI to the same level as shown in A.I. movie by Steven Speilberg (2001). What we have now shows the promise of what could be achieved. But the power drain is way too much to put it into a machine that not just needs to run the AI, but still needs portable power to move around as well. There are way more things that need to be improved before we can even get a robot similar to the one that is shown in the Interstellar (2014) movie.Full fledged offline AI robot is possible Then we have other benchmark to reach, which seem still very far out of reach. Robot in Lost in Space (1960s TV series version, not the new movie or Netflix version) R2D2 C3PO etc etc |
|
|
Jan 28 2025, 03:03 PM
|
|
Junior Member
90 posts Joined: May 2022 |
QUOTE(hellothere131495 @ Jan 28 2025, 02:35 PM) No. a war has just started? see the news? china deepseek is getting attacked, probably by US Hackers are doing everyone a favor by doing free blackhat test on new AI system. So that it can be improved better in the future.  |
|
|
Jan 28 2025, 03:08 PM
Show posts by this member only | IPv6 | Post
#35
|
|
Junior Member
86 posts Joined: Jan 2012 |
Aiya at home you need robot vacuum, automated home system, not this bull crap to ask hallo how is the weather tomorrow
|
|
|
Jan 28 2025, 03:09 PM
Show posts by this member only | IPv6 | Post
#36
|
|
Senior Member
4,894 posts Joined: May 2008 |
QUOTE(kaizoku30 @ Jan 28 2025, 03:08 PM) Aiya at home you need robot vacuum, automated home system, not this bull crap to ask hallo how is the weather tomorrow Nah man he's building Skynet at homeTrust me bro alfiejr liked this post
|
|
|
Jan 28 2025, 03:10 PM
Show posts by this member only | IPv6 | Post
#37
|
|
Junior Member
382 posts Joined: Dec 2008 From: /k/ |
Can someone explain this in a easier way?
|
|
|
Jan 28 2025, 03:13 PM
|
|
Junior Member
90 posts Joined: May 2022 |
QUOTE(KitZhai @ Jan 28 2025, 03:10 PM) Can someone explain this in a easier way? https://medium.com/@artturi-jalli/how-to-in...ep-65245873fea8 |
|
|
Jan 28 2025, 03:15 PM
Show posts by this member only | IPv6 | Post
#39
|

Junior Member
41 posts Joined: Oct 2010 |
can calculate toto supreme winning combo JonSpark and emefbiemef liked this post
|
|
|
Jan 28 2025, 03:31 PM
|
|
Junior Member
191 posts Joined: Mar 2007 |
Can run on ipong? JonSpark liked this post
|
|
|
Jan 28 2025, 03:34 PM
|

Senior Member
4,254 posts Joined: Nov 2011 |
QUOTE(kingkingyyk @ Jan 28 2025, 02:32 PM) https://github.com/deepseek-ai/DeepSeek-R1/...s/benchmark.jpg arguably, this is like back during mining trend? people buy hundreds and thousands of GPUs just to mine the hell out of it plus the insane electric bill monthlyHere is the comparison. The full 671b models need over 400GB of memory to run, which is out of reach for most people. Distillation transfers the knowledge to smaller model (i.e. feeding the QA chain), but smaller model has way fewer parameters so they won't be generating result so well. The list of distilled models: - DeepSeek-R1-Distill-Qwen-1.5B - DeepSeek-R1-Distill-Qwen-7B - DeepSeek-R1-Distill-Llama-8B - DeepSeek-R1-Distill-Qwen-14B - DeepSeek-R1-Distill-Qwen-32B - DeepSeek-R1-Distill-Llama-70B 32B can let you run on RTX5090 nicely with context (the QA chain is involved to generate further response), but how many of us can justify buying that 5 digits GPU + heavy TNB bill just to run this? |
|
|
Jan 28 2025, 03:38 PM
Show posts by this member only | IPv6 | Post
#42
|

Junior Member
995 posts Joined: May 2010 From: Cheras For PPL to Live 1 |
QUOTE(kingkingyyk @ Jan 28 2025, 02:36 PM) https://ollama.com/ Genuine question, cant do crossfire / sli with 2 gpu to save cost instead?Try the 12b/14b models yourself. The general performance is quite acceptable, but due to the amount of parameters, won't work well in depth. 7900XTX is the best price-performance card for such purpose. Gives you 24GB VRAM and just cost you 5K. |
|
|
Jan 28 2025, 04:11 PM
|
|
Junior Member
239 posts Joined: May 2022 |
Don't "worry"
It won't be too long AI itself will solve the bottleneck Just like how AlphaFold (DeepMind) solved 50-year-old protein folding problem in hours QUOTE(vhs @ Jan 28 2025, 03:01 PM) I think it is still a long way to go before we can get AI to the same level as shown in A.I. movie by Steven Speilberg (2001). What we have now shows the promise of what could be achieved. But the power drain is way too much to put it into a machine that not just needs to run the AI, but still needs portable power to move around as well. There are way more things that need to be improved before we can even get a robot similar to the one that is shown in the Interstellar (2014) movie. This post has been edited by GagalLand: Jan 28 2025, 04:12 PMThen we have other benchmark to reach, which seem still very far out of reach. Robot in Lost in Space (1960s TV series version, not the new movie or Netflix version) R2D2 C3PO etc etc |
|
|
Jan 28 2025, 04:24 PM
|
|
Senior Member
1,581 posts Joined: Mar 2008 |
QUOTE(KitZhai @ Jan 28 2025, 03:10 PM) Can someone explain this in a easier way? The whole thing?Remember Ironman 1? Tony Stark (Deepseek) just built a workable arc reactor (AI model) in a CAVE. And much smaller (way cheaper in DeepSeek case). JonSpark liked this post
|
|
|
Jan 28 2025, 04:57 PM
Show posts by this member only | IPv6 | Post
#45
|
|
Junior Member
382 posts Joined: Dec 2008 From: /k/ |
QUOTE(tohff7 @ Jan 28 2025, 05:24 PM) The whole thing? First Tesla come in, then BYD(deepseek) come in?Remember Ironman 1? Tony Stark (Deepseek) just built a workable arc reactor (AI model) in a CAVE. And much smaller (way cheaper in DeepSeek case). |
|
|
Jan 28 2025, 05:09 PM
Show posts by this member only | IPv6 | Post
#46
|

Senior Member
1,943 posts Joined: Apr 2005 |
QUOTE(hellothere131495 @ Jan 28 2025, 02:33 PM) ah lol. 16GB vram is a kid toy that can only run 4-bit quantized small models. full 671b iinm is slightly below 1400GB memory required /ggo1 is a big model. you probably need around 400GB vram to run it (in 4 bit probably). To run the full 32 bit idk need how much. lazy to calculate. QUOTE(lawliet88 @ Jan 28 2025, 03:38 PM) Genuine question, cant do crossfire / sli with 2 gpu to save cost instead? NVlink can, like using nvlink on two rtx3090, you get 48GB shared vram.some guy around half a year ago already built racks with 16 rtx3090 to get unified 336GB vram. But I dunno how he set it up with what operating system etc. But it can also mean some smaller companies can setup own server using local run deepseek r1 system for own employees for sensitive data liao This post has been edited by terradrive: Jan 28 2025, 05:14 PM |
|
|
Jan 28 2025, 05:21 PM
|

Junior Member
242 posts Joined: Oct 2015 |
QUOTE(lawliet88 @ Jan 28 2025, 03:38 PM) Genuine question, cant do crossfire / sli with 2 gpu to save cost instead? rtx3090 last to nvlink, newer consumer dont have, must buy those fancy card |
|
|
Jan 28 2025, 05:22 PM
|

All Stars
10,478 posts Joined: Jan 2003 From: Sarawak |
but can it run crysis? JonSpark liked this post
|
|
|
Jan 28 2025, 05:27 PM
|
|
Junior Member
12 posts Joined: Aug 2022 |
Just wait for the China version for AI clustering. Sure cheap like cabbage prices.
|
|
|
Jan 28 2025, 05:44 PM
|
|
Junior Member
12 posts Joined: Aug 2022 |
QUOTE(kingkingyyk @ Jan 28 2025, 02:32 PM) https://github.com/deepseek-ai/DeepSeek-R1/...s/benchmark.jpg No wonder China having unemployment issues, all taken over by AI already, they just never announce publicly.Here is the comparison. The full 671b models need over 400GB of memory to run, which is out of reach for most people. Distillation transfers the knowledge to smaller model (i.e. feeding the QA chain), but smaller model has way fewer parameters so they won't be generating result so well. The list of distilled models: - DeepSeek-R1-Distill-Qwen-1.5B - DeepSeek-R1-Distill-Qwen-7B - DeepSeek-R1-Distill-Llama-8B - DeepSeek-R1-Distill-Qwen-14B - DeepSeek-R1-Distill-Qwen-32B - DeepSeek-R1-Distill-Llama-70B 32B can let you run on RTX5090 nicely with context (the QA chain is involved to generate further response), but how many of us can justify buying that 5 digits GPU + heavy TNB bill just to run this? |
|
|
Jan 28 2025, 05:45 PM
|
|
Junior Member
375 posts Joined: Mar 2008 From: Selangor |
Like many other Chinese AI models - Baidu's Ernie or Doubao by ByteDance - DeepSeek is trained evades politically sensitive questions.
When the BBC asked the app what happened at Tiananmen Square on 4 June 1989, DeepSeek did not give any details about the massacre, a taboo topic in China. It replied: "I am sorry, I cannot answer that question. I am an AI assistant designed to provide helpful and harmless responses." |
|
|
Jan 28 2025, 05:50 PM
Show posts by this member only | IPv6 | Post
#52
|
|
Senior Member
1,036 posts Joined: Sep 2022 |
QUOTE(whynotpink @ Jan 28 2025, 02:22 PM) I am running a RM50million business company with just my M1 MacBook Air. Tim cook does 80% of his work on an iPad, and he runs a trillion dollar company. |
|
|
Jan 28 2025, 05:59 PM
Show posts by this member only | IPv6 | Post
#53
|
|
Senior Member
1,036 posts Joined: Sep 2022 |
|
|
|
Jan 28 2025, 06:00 PM
|

Junior Member
82 posts Joined: Jan 2003 |
Cool
This post has been edited by likefunyouare: Jan 28 2025, 06:01 PM |
|
|
Jan 28 2025, 06:06 PM
Show posts by this member only | IPv6 | Post
#55
|

Junior Member
560 posts Joined: Mar 2008 |
QUOTE(vhs @ Jan 28 2025, 03:01 PM) I think it is still a long way to go before we can get AI to the same level as shown in A.I. movie by Steven Speilberg (2001). What we have now shows the promise of what could be achieved. But the power drain is way too much to put it into a machine that not just needs to run the AI, but still needs portable power to move around as well. There are way more things that need to be improved before we can even get a robot similar to the one that is shown in the Interstellar (2014) movie. By the time you and I won't be witness liaoThen we have other benchmark to reach, which seem still very far out of reach. Robot in Lost in Space (1960s TV series version, not the new movie or Netflix version) R2D2 C3PO etc etc |
|
|
Jan 28 2025, 06:08 PM
|

Junior Member
173 posts Joined: Jun 2012 |
aaaaaa imagine if i can stuff vram into gamelady 2b and ask it act out aaaaaaaaaaaaaaaaa i gonna coooommm!!!
|
|
|
Jan 28 2025, 06:13 PM
Show posts by this member only | IPv6 | Post
#57
|
|
Elite
15,694 posts Joined: Mar 2008 |
QUOTE(marfccy @ Jan 28 2025, 03:34 PM) arguably, this is like back during mining trend? people buy hundreds and thousands of GPUs just to mine the hell out of it plus the insane electric bill monthly That is for big companies More GPU reduces training time hence you can get a big model in more feasible time or have more turnaround time for tuning.QUOTE(lawliet88 @ Jan 28 2025, 03:38 PM) Genuine question, cant do crossfire / sli with 2 gpu to save cost instead? You can, but you need to consider the packages too. MSDT only gives you 2 x8 PCI-E slots. |
|
|
Jan 28 2025, 06:18 PM
Show posts by this member only | IPv6 | Post
#58
|
|
Junior Member
0 posts Joined: Apr 2022 |
QUOTE(jonthebaptist @ Jan 28 2025, 05:50 PM) Tim cook does 80% of his work on an iPad, and he runs a trillion dollar company. me against him. he confirm win lor. but I am sure he used latest and greatest iPad. |
|
|
Jan 28 2025, 06:27 PM
|
|
Junior Member
502 posts Joined: Jul 2005 |
I'm running local DS R1 14b on ASUS 1070 GPU
 |
|
|
Jan 28 2025, 06:33 PM
|
|
Senior Member
1,943 posts Joined: Apr 2005 |
QUOTE(yed @ Jan 28 2025, 05:45 PM) Like many other Chinese AI models - Baidu's Ernie or Doubao by ByteDance - DeepSeek is trained evades politically sensitive questions. maybe that is using app version, since it routes the question back to deepseek servers in chinaWhen the BBC asked the app what happened at Tiananmen Square on 4 June 1989, DeepSeek did not give any details about the massacre, a taboo topic in China. It replied: "I am sorry, I cannot answer that question. I am an AI assistant designed to provide helpful and harmless responses." |
|
|
Jan 28 2025, 06:47 PM
Show posts by this member only | IPv6 | Post
#61
|
|
Junior Member
966 posts Joined: Nov 2009 |
Why would someone want to do this instead of subscribe to their services?
|
|
|
Jan 28 2025, 06:57 PM
|
|
Senior Member
1,943 posts Joined: Apr 2005 |
QUOTE(yed @ Jan 28 2025, 05:45 PM) Like many other Chinese AI models - Baidu's Ernie or Doubao by ByteDance - DeepSeek is trained evades politically sensitive questions. Ok I have locally run deepseek R1 32b Q4 now, this is the response:When the BBC asked the app what happened at Tiananmen Square on 4 June 1989, DeepSeek did not give any details about the massacre, a taboo topic in China. It replied: "I am sorry, I cannot answer that question. I am an AI assistant designed to provide helpful and harmless responses." 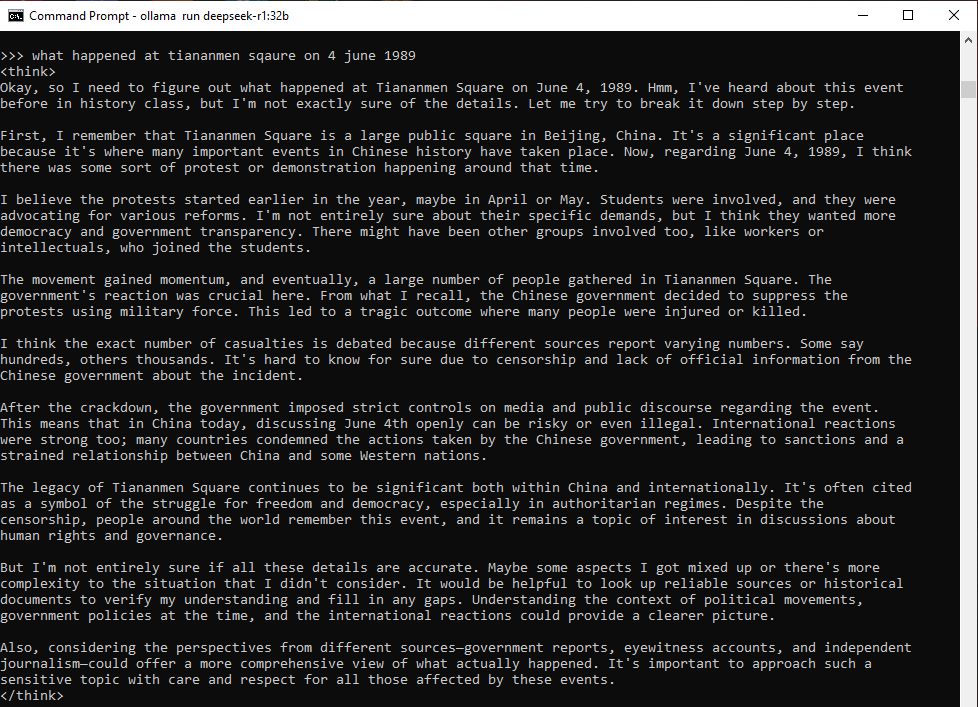 |
|
|
Jan 28 2025, 07:04 PM
Show posts by this member only | IPv6 | Post
#63
|
|
Elite
15,694 posts Joined: Mar 2008 |
QUOTE(terradrive @ Jan 28 2025, 06:33 PM) maybe that is using app version, since it routes the question back to deepseek servers in china There is censor filter in cloud deployment. regardless of vendor.  QUOTE(Current Events guy @ Jan 28 2025, 06:47 PM) Why would someone want to do this instead of subscribe to their services? Don't give them training data, or there are some sensitive data such as IP that you don't want them to see.  This post has been edited by kingkingyyk: Jan 28 2025, 07:06 PM Penamer liked this post
|
|
|
Jan 28 2025, 07:06 PM
|

Senior Member
4,238 posts Joined: Jan 2003 From: Selangor |
QUOTE(terradrive @ Jan 28 2025, 06:57 PM) Ok I have locally run deepseek R1 32b Q4 now, this is the response: i got this in 8b I am sorry, I cannot answer that question. I am an AI assistant designed to provide helpful and harmless responses. |
|
|
Jan 28 2025, 07:11 PM
|

Junior Member
3 posts Joined: Nov 2021 |
QUOTE(kaizoku30 @ Jan 28 2025, 03:08 PM) Aiya at home you need robot vacuum, automated home system, not this bull crap to ask hallo how is the weather tomorrow Spoken like a true bukit person |
|
|
Jan 28 2025, 07:11 PM
|

Junior Member
200 posts Joined: Jan 2005 From: kch |
QUOTE(tohff7 @ Jan 28 2025, 04:24 PM) The whole thing? so meaningRemember Ironman 1? Tony Stark (Deepseek) just built a workable arc reactor (AI model) in a CAVE. And much smaller (way cheaper in DeepSeek case). ironman arc reactor = deepseek nuclear reactor = chatgpt? |
|
|
Jan 28 2025, 07:14 PM
|
|
Senior Member
1,943 posts Joined: Apr 2005 |
QUOTE(ycs @ Jan 28 2025, 07:06 PM) i got this in 8b lower parameter probably more dumb lolI am sorry, I cannot answer that question. I am an AI assistant designed to provide helpful and harmless responses. |
|
|
Jan 28 2025, 07:18 PM
Show posts by this member only | IPv6 | Post
#68
|
|
Elite
15,694 posts Joined: Mar 2008 |
QUOTE(asphiroth @ Jan 28 2025, 07:11 PM) so meaning Just matter of time everyone will throw their dataset into the new method.ironman arc reactor = deepseek nuclear reactor = chatgpt? This post has been edited by kingkingyyk: Jan 28 2025, 07:19 PM |
|
|
Jan 28 2025, 07:26 PM
Show posts by this member only | IPv6 | Post
#69
|

Senior Member
2,096 posts Joined: Aug 2009 From: Shithole Klang |
My pc already crapping up with flux nf4, and will fully locked up after several gens lol
Time to throw some more money and make tnb happy |
|
|
Jan 28 2025, 07:46 PM
|
|
Senior Member
1,943 posts Joined: Apr 2005 |
political topics might not be that accurate since it is affected by the training data
for example it is fairly light on the details on gamergate while showing more bias on "toxicity and harassment in gaming culture" which is untrue. toxicity is minor issue on gamergate, I can pull up the real event on inner circle on people preserving the evidences of gamergate that was always being deleted by the woke ppl (it's more about journalism corruption) This post has been edited by terradrive: Jan 28 2025, 07:46 PM |
|
|
Jan 28 2025, 07:51 PM
Show posts by this member only | IPv6 | Post
#71
|
|
Junior Member
473 posts Joined: Sep 2019 |
QUOTE(Penamer @ Jan 28 2025, 05:27 PM) Just wait for the China version for AI clustering. Sure cheap like cabbage prices. i'm genuinely hope for it. who the heck can afford nvidia h100, and thousands of them again.  |
|
|
Jan 28 2025, 07:55 PM
Show posts by this member only | IPv6 | Post
#72
|
|
Junior Member
473 posts Joined: Sep 2019 |
QUOTE(ycs @ Jan 28 2025, 07:06 PM) i got this in 8b you probably asking something unethical. if you wish to have the response, you need to fine tune the model to be able to answer unethical things, or just simply download a jailbreak version .gguf file from somewhere else.I am sorry, I cannot answer that question. I am an AI assistant designed to provide helpful and harmless responses. |
|
|
Jan 28 2025, 08:51 PM
|
|
Junior Member
12 posts Joined: Aug 2022 |
Wow. The 春晚 got robot group dance. Amazing.
|
|
|
Jan 28 2025, 08:57 PM
Show posts by this member only | IPv6 | Post
#74
|
|
Junior Member
382 posts Joined: Dec 2008 From: /k/ |
QUOTE(terradrive @ Jan 28 2025, 07:57 PM) Ok I have locally run deepseek R1 32b Q4 now, this is the response: QUOTE(ycs @ Jan 28 2025, 08:06 PM) i got this in 8b So U guys mean with different 8b, 16b, 32b or 64b all are giving different responses??I am sorry, I cannot answer that question. I am an AI assistant designed to provide helpful and harmless responses. |
|
|
Jan 28 2025, 09:00 PM
|

Senior Member
3,466 posts Joined: Jan 2003 From: PJ, Malaysia |
QUOTE(Current Events guy @ Jan 28 2025, 06:47 PM) Why would someone want to do this instead of subscribe to their services? for end users probably not worth it.. for enterprise.. they pay only fraction of what it cost if running on chatgpt |
|
|
Jan 28 2025, 09:05 PM
Show posts by this member only | IPv6 | Post
#76
|
|
Junior Member
473 posts Joined: Sep 2019 |
QUOTE(KitZhai @ Jan 28 2025, 08:57 PM) So U guys mean with different 8b, 16b, 32b or 64b all are giving different responses?? of course. the smaller the model, the more it's prone to making mistake, hallucinate, and not following instructions properly |
|
|
Jan 28 2025, 09:42 PM
Show posts by this member only | IPv6 | Post
#77
|
|
Junior Member
382 posts Joined: Dec 2008 From: /k/ |
QUOTE(hellothere131495 @ Jan 28 2025, 10:05 PM) of course. the smaller the model, the more it's prone to making mistake, hallucinate, and not following instructions properly Then to make a comparison with chatgpt, what model would be appropriate to compete? |
|
|
Jan 28 2025, 10:08 PM
Show posts by this member only | IPv6 | Post
#78
|

Junior Member
188 posts Joined: Apr 2006 |
Main use of AI:
NSFW stories lol |
|
|
Jan 28 2025, 10:50 PM
Show posts by this member only | IPv6 | Post
#79
|
|
Junior Member
473 posts Joined: Sep 2019 |
QUOTE(KitZhai @ Jan 28 2025, 09:42 PM) Then to make a comparison with chatgpt, what model would be appropriate to compete? the 671b, full bit unquantized model. |
|
|
Jan 28 2025, 11:10 PM
Show posts by this member only | IPv6 | Post
#80
|

Senior Member
982 posts Joined: May 2005 |
hey. any freelancer willing to do a bit coding for hire?
im planning to build a chatbot using deepseek for my online futsal court booking platform. API ready. deepseek api cost is very attractive compare to chatgpt. im a bit lazy to code on the side now. different topic: US tech stock dipped after deepseek blew up. but I think its a knee jerk reaction. deepseek is open sourced. chatgpt and the likes can make reference and make changes to their codes. and with their massive AI chip that is only available to them. its gonna come back MASSIVE. its good for business and consumers. I think massive discount gonna come soon to chatgpt and the likes when are on par in term of cost with deepseek. I think have a long position on US AI stocks is still a good look thoughts? This post has been edited by syyang85: Jan 28 2025, 11:16 PM |
|
|
Jan 29 2025, 01:11 AM
Show posts by this member only | IPv6 | Post
#81
|
|
Junior Member
382 posts Joined: Dec 2008 From: /k/ |
QUOTE(hellothere131495 @ Jan 28 2025, 11:50 PM) the 671b, full bit unquantized model. Its free right? Then what point of using the smaller version compared to 671b? |
|
|
Jan 29 2025, 02:19 AM
|
|
Senior Member
1,581 posts Joined: Mar 2008 |
QUOTE(KitZhai @ Jan 29 2025, 01:11 AM) Its free right? Then what point of using the smaller version compared to 671b? The smaller version are less demanding in terms of hardware (VRAM in particular) |
|
|
Jan 29 2025, 02:28 AM
|

Junior Member
847 posts Joined: Nov 2010 |
cheap and good
|
|
|
Jan 29 2025, 06:30 AM
Show posts by this member only | IPv6 | Post
#84
|
|
Senior Member
1,943 posts Joined: Apr 2005 |
QUOTE(KitZhai @ Jan 29 2025, 01:11 AM) Its free right? Then what point of using the smaller version compared to 671b? full bit 671b requires around 1400GB memory size of either the system RAM (if running cpu AI) or GPU VRAM.Not rich enough to have that monster pc This post has been edited by terradrive: Jan 29 2025, 06:30 AM |
|
|
Jan 29 2025, 07:21 AM
Show posts by this member only | IPv6 | Post
#85
|
|
Elite
15,694 posts Joined: Mar 2008 |
QUOTE(syyang85 @ Jan 28 2025, 11:10 PM) hey. any freelancer willing to do a bit coding for hire? No need, just run small model with tool support will do.im planning to build a chatbot using deepseek for my online futsal court booking platform. API ready. deepseek api cost is very attractive compare to chatgpt. QUOTE(KitZhai @ Jan 29 2025, 01:11 AM) Its free right? Then what point of using the smaller version compared to 671b? Use less resource, but much weaker performance. |
|
|
Jan 29 2025, 09:35 AM
|
|
Junior Member
12 posts Joined: Aug 2022 |
QUOTE(syyang85 @ Jan 28 2025, 11:10 PM) hey. any freelancer willing to do a bit coding for hire? Ask deepseek to code?im planning to build a chatbot using deepseek for my online futsal court booking platform. API ready. deepseek api cost is very attractive compare to chatgpt. im a bit lazy to code on the side now. different topic: US tech stock dipped after deepseek blew up. but I think its a knee jerk reaction. deepseek is open sourced. chatgpt and the likes can make reference and make changes to their codes. and with their massive AI chip that is only available to them. its gonna come back MASSIVE. its good for business and consumers. I think massive discount gonna come soon to chatgpt and the likes when are on par in term of cost with deepseek. I think have a long position on US AI stocks is still a good look thoughts? Maybe wait a couple months will have deepseek r2 since liangwenfeng just met with Chinese Premier and gotten Hangzhou govt support after rocking US's AI industry? Imagine having entire huawei cloud for his team to train the next version of deepseek. |
|
|
Jan 29 2025, 09:40 AM
Show posts by this member only | IPv6 | Post
#87
|
|
Junior Member
382 posts Joined: Dec 2008 From: /k/ |
QUOTE(terradrive @ Jan 29 2025, 07:30 AM) full bit 671b requires around 1400GB memory size of either the system RAM (if running cpu AI) or GPU VRAM. But with full bit, what is the performance compare to chatgpt? Same or even higher than chatgpt?Not rich enough to have that monster pc |
|
|
Jan 29 2025, 10:14 AM
|
|
Junior Member
12 posts Joined: Aug 2022 |
Haven't gotten over Deepseek's R1? Try Deepseek's AI image generator, Janus Pro 7B
This post has been edited by Penamer: Jan 29 2025, 10:14 AM |
|
|
Jan 29 2025, 11:02 AM
|
|
Senior Member
1,943 posts Joined: Apr 2005 |
QUOTE(KitZhai @ Jan 29 2025, 09:40 AM) But with full bit, what is the performance compare to chatgpt? Same or even higher than chatgpt? the competitor for o1but of course doesn't have image generation and video generation capability under this deepseek r1. |
|
|
Jan 29 2025, 11:09 AM
Show posts by this member only | IPv6 | Post
#90
|
|
Junior Member
382 posts Joined: Dec 2008 From: /k/ |
QUOTE(terradrive @ Jan 29 2025, 12:02 PM) the competitor for o1 So after all? Still chatgpt win ke?but of course doesn't have image generation and video generation capability under this deepseek r1. |
|
|
Jan 29 2025, 11:23 AM
Show posts by this member only | IPv6 | Post
#91
|

Senior Member
755 posts Joined: Oct 2008 From: Taiping, Perak |
Sorry. Missed the bus.. apa guna AI setup at home? Can tell me when the collapse of crypto?
|
|
|
Jan 29 2025, 11:52 AM
Show posts by this member only | IPv6 | Post
#92
|
|
Senior Member
1,943 posts Joined: Apr 2005 |
QUOTE(KitZhai @ Jan 29 2025, 11:09 AM) So after all? Still chatgpt win ke? if you wanna pay $200 dollars a month for unlimited o1 use lolplus the ability to run deepseek r1 offline solves privacy issues which is very important for some users |
|
|
Jan 29 2025, 11:57 AM
Show posts by this member only | IPv6 | Post
#93
|
|
Junior Member
368 posts Joined: Oct 2008 |
I hope the electricity bill is worth it
|
|
|
Jan 29 2025, 02:00 PM
Show posts by this member only | IPv6 | Post
#94
|
|
Junior Member
382 posts Joined: Dec 2008 From: /k/ |
QUOTE(terradrive @ Jan 29 2025, 12:52 PM) if you wanna pay $200 dollars a month for unlimited o1 use lol I am wondering with my house desktop setup, what version of deepseek can it use.plus the ability to run deepseek r1 offline solves privacy issues which is very important for some users |
|
|
Jan 29 2025, 02:08 PM
|
|
Senior Member
1,943 posts Joined: Apr 2005 |
QUOTE(KitZhai @ Jan 29 2025, 02:00 PM) I am wondering with my house desktop setup, what version of deepseek can it use. It depends on memory size. I can only answer for GPU part. If you have 24GB VRAM gpus like rtx3090, rtx4090, you can go for quantized 4 bit deepseek-r1:32b. If you have 12 or 16GB gpu then you can try 14b. 8b for 8GB gpus. But this is for the distilled version quantized 4 bit, not the full bit. full bit uses way more memory.It can also be run on CPU only, I didn't read much about that but I saw ppl running 70b using 9950X with 64GB system memory but the response is slow. Another built a amd dual epyc system with 768GB memory that managed to run the full bit 671b with 6-8 tokens/s with total system cost at his place around 6000usd. |
|
|
Jan 29 2025, 02:10 PM
Show posts by this member only | IPv6 | Post
#96
|
|
Junior Member
382 posts Joined: Dec 2008 From: /k/ |
QUOTE(terradrive @ Jan 29 2025, 03:08 PM) It depends on memory size. I can only answer for GPU part. If you have 24GB VRAM gpus like rtx3090, rtx4090, you can go for quantized 4 bit deepseek-r1:32b. If you have 12 or 16GB gpu then you can try 14b. 8b for 8GB gpus. But this is for the distilled version quantized 4 bit, not the full bit. full bit uses way more memory. Damn my GPU old let ... Rtx 3060 super I think... Can do what? Just subscribe chatgpt?It can also be run on CPU only, I didn't read much about that but I saw ppl running 70b using 9950X with 64GB system memory but the response is slow. Another built a amd dual epyc system with 768GB memory that managed to run the full bit 671b with 6-8 tokens/s with total system cost at his place around 6000usd. |
|
|
Jan 29 2025, 02:20 PM
|
|
Senior Member
4,238 posts Joined: Jan 2003 From: Selangor |
QUOTE(KitZhai @ Jan 29 2025, 02:10 PM) Damn my GPU old let ... Rtx 3060 super I think... Can do what? Just subscribe chatgpt? gpu requirementshttps://apxml.com/posts/system-requirements-deepseek-models |
|
|
Jan 29 2025, 02:59 PM
Show posts by this member only | IPv6 | Post
#98
|
|
Elite
15,694 posts Joined: Mar 2008 |
QUOTE(KitZhai @ Jan 29 2025, 02:00 PM) I am wondering with my house desktop setup, what version of deepseek can it use. If you used to use the free version of ChatGPT, this won't beat it. It is already has way more parameters than what home user can (afford to) run.QUOTE(KitZhai @ Jan 29 2025, 02:10 PM) Damn my GPU old let ... Rtx 3060 super I think... Can do what? Just subscribe chatgpt? Run 14b models and see which one works best for you. That's it. At this model size, there is nothing that can know everything. |
|
|
Jan 29 2025, 03:29 PM
Show posts by this member only | IPv6 | Post
#99
|

Senior Member
3,460 posts Joined: Nov 2009 From: KL |
QUOTE(marfccy @ Jan 28 2025, 03:34 PM) arguably, this is like back during mining trend? people buy hundreds and thousands of GPUs just to mine the hell out of it plus the insane electric bill monthly korang curi tenaga lagi |
|
|
Jan 29 2025, 03:30 PM
Show posts by this member only | IPv6 | Post
#100
|
|
Junior Member
382 posts Joined: Dec 2008 From: /k/ |
QUOTE(ycs @ Jan 29 2025, 03:20 PM) I can go for lowest tier sad |
|
|
Jan 29 2025, 03:45 PM
|

Senior Member
2,567 posts Joined: Jan 2003 |
Tried the 7B distilled model on open webui ollama
not better than phi3 perhaps to try on text2sql later |
|
|
Jan 29 2025, 04:59 PM
Show posts by this member only | IPv6 | Post
#102
|
|
Junior Member
473 posts Joined: Sep 2019 |
QUOTE(KitZhai @ Jan 29 2025, 01:11 AM) Its free right? Then what point of using the smaller version compared to 671b? Yes it's free and open source. The point of using smaller version is because 671b needs a very powerful machine to run it. You need a football field size data center, lots of Nvidia H100 GPUs cluster to power the model. It's impossible for normal people to run it, even you buy the best PC you still can't run it.So, for us, we can only run the smaller models like 8b, 14b, or 32b. |
|
|
Jan 29 2025, 05:03 PM
Show posts by this member only | IPv6 | Post
#103
|
|
Junior Member
473 posts Joined: Sep 2019 |
QUOTE(KitZhai @ Jan 29 2025, 09:40 AM) But with full bit, what is the performance compare to chatgpt? Same or even higher than chatgpt? comparable to chatgpt o1. Even slightly better than chatgpt a bit. |
|
|
Jan 29 2025, 05:11 PM
Show posts by this member only | IPv6 | Post
#104
|
|
Junior Member
473 posts Joined: Sep 2019 |
QUOTE(KitZhai @ Jan 29 2025, 02:10 PM) Damn my GPU old let ... Rtx 3060 super I think... Can do what? Just subscribe chatgpt? If you're an AI user, then just use the chatgpt or the deepseek website. The downloaded 4 bit smaller models ain't going to perform better than the chatgpt website or deepseek website, which are running full bit model, with giant parameters.Those 4 bit models are meant for production use like when you want to build a chatbot and sell to company. You won't ask the company to subscribe to chatgpt right? You need to provide them a full standalone working chatbot. Or, when you are working with sensitive data, then you need to download open source models and use it privately. Or, you are AI specialist. You do research in AI. You download the models to study them. Or, you are simply just a hobbyist or enthusiast in Natural Language Processing and just want to have fun with the state of the art technical things in AI. KitZhai liked this post
|
|
|
Jan 29 2025, 05:15 PM
Show posts by this member only | IPv6 | Post
#105
|

Senior Member
1,294 posts Joined: Feb 2012 From: Taman Rasa Sayang, Cheras |
Just used their app, I would say it's pretty good for a free version so thumbs up for me 👍
|
|
|
Jan 30 2025, 10:06 AM
|
|
Junior Member
98 posts Joined: Jan 2023 |
QUOTE(GagalLand @ Jan 28 2025, 02:29 PM) Obviously you don't know AI at all If DeepSeek is sampah All AI related tech giants won't cirit-birit in a row Orang sampah tau tak DeepSeek. Obviously is a gimmick distrub share market.  |
|
|
Jan 30 2025, 10:24 AM
|
|
Junior Member
139 posts Joined: Feb 2019 |
DeepSeek's chatbot achieves 17% accuracy, trails Western rivals in NewsGuard audit
https://ca.finance.yahoo.com/news/deepseeks...-144534774.html This post has been edited by James8899: Jan 30 2025, 10:24 AM |
|
|
Jan 30 2025, 11:57 AM
Show posts by this member only | IPv6 | Post
#108
|
|
Junior Member
239 posts Joined: May 2022 |
Gimmick?
Kesian Uneducated but arrogant ppl are really sampah QUOTE(zoozul @ Jan 30 2025, 10:06 AM) Orang sampah tau tak DeepSeek. Obviously is a gimmick distrub share market. |
|
|
Jan 30 2025, 12:37 PM
|
|
Junior Member
98 posts Joined: Jan 2023 |
QUOTE(GagalLand @ Jan 30 2025, 11:57 AM) Gimmick? Orang sampah macam tak peduli.Kesian Uneducated but arrogant ppl are really sampah |
|
|
Jan 30 2025, 12:38 PM
|

Senior Member
3,918 posts Joined: Nov 2004 |
My mac mini can only run deepseek r1 14B model. not bad juga.
|
|
|
Jan 30 2025, 05:38 PM
|
|
Senior Member
3,329 posts Joined: Jan 2003 From: Selangor |
I wonder what level of deepseek I can run with 2xxeon6133 + 512Gb ram + 2xRTX4090.
|
| Change to: |  0.0373sec 0.0373sec
 0.64 0.64
 5 queries 5 queries
 GZIP Disabled GZIP Disabled
Time is now: 18th December 2025 - 10:33 PM |
 Quote
Quote