

 Jun 14 2025, 12:41 AM
Jun 14 2025, 12:41 AM

QUOTE(c2tony @ Jun 13 2025, 10:36 PM)
8700G = 16 TOPS
ryzen ai max+ 395 = 55 TOPS
RTX3060 12GB = 100 TOPS
Apple Mac Studio M4 Max = 38 TOPS
They all can run.
BTW, 55 TOPS may sound like more AI power than 38 TOPS,
the way Apple handles data and optimizes usage can deliver equivalent or faster AI execution
Even if your PC has 128GB of RAM, your GPU might be capped by its 24GB VRAM when loading a large AI model
With Apple’s unified memory, you might comfortably run a llama4:16x17b entirely in GPU addressable space if you have 96GB of ram.

The bigger the model, the more capable GPU/NPU/CPU it needs in addition to the memory bandwidth.ryzen ai max+ 395 = 55 TOPS
RTX3060 12GB = 100 TOPS
Apple Mac Studio M4 Max = 38 TOPS
They all can run.
BTW, 55 TOPS may sound like more AI power than 38 TOPS,
the way Apple handles data and optimizes usage can deliver equivalent or faster AI execution
Even if your PC has 128GB of RAM, your GPU might be capped by its 24GB VRAM when loading a large AI model
With Apple’s unified memory, you might comfortably run a llama4:16x17b entirely in GPU addressable space if you have 96GB of ram.
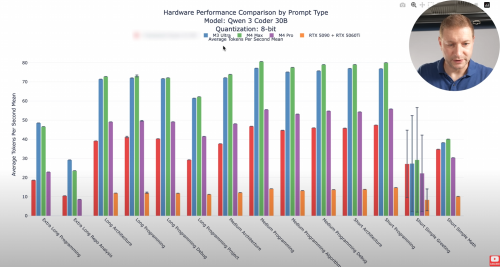
The RTX PRO 6000 videos shows when he's running Qwen2.5 Coder 32B FP16 with the size of 61GB, even M4 Max with memory bandwidth of 500GB/second only getting 7.63 tokens/second while the RTX PRO 6000 still getting good speed with 23 tokens/second. Ryzen AI Max+ 395 he uses Qwen2.5 Coder 32B q4_k_m which is only 20GB but only getting 10.8 tokens/second. This 395 CPU is very capable but it's limited by the memory bandwidth.
 Quote
Quote




















 0.0163sec
0.0163sec
 1.00
1.00
 6 queries
6 queries
 GZIP Disabled
GZIP Disabled