QUOTE(adilz @ Jun 4 2016, 08:26 PM)
Bro, sorry had to correct you here. Async compute is one the new features available in DX12, but not in DX11. Nvidia previous Maxwell GPU does not support Async Compute in DX12, like AMD Fiji GPU. For the case of Ashes of Singularity, it can run in DX11 or DX12. And in DX12, Async Compute can be enabled and disabled. It was AoTs benchmark which highlighted the Maxwell Async Compute issues. There are quite a number of analysis, but here are few, generally between GTX 980 Ti vs Fury X.
There seems to be some misunderstanding on what the DX12 async compute enabled or disabled means..
Most of the "async compute" is referring to the scheduling method. Not whether the GPU can have both graphic and compute tasks processed at the same time. What DX12 enables is allowing work to be dispatched concurrently. If no work is being dispatched to the compute unit, it will idle.
Traditionally, DX11 has a single hardware work queue. The CPU will see only a single queue to submit task to. Queue is basically a list of pending task waiting to be send to GPU compute units to be processed.
Say you have 3 streams of tasks.
CODE
Stream ABC - graphic
Stream DEF - compute
Stream GHI - compute
Stream ABC is independent of DEF so theoretically it can work in parallel on different compute units.
In DX11 with a single work queue,
Step 1: the CPU will submit ABC | DEF | GHI to this work queue sequentially. The GPU can only know if the task can be processed concurrently when it reaches the scheduler.
CODE
DX11 CPU to GPU Hardware queue: ABC | DEF | GHI
Step 2: The GPU scheduler will dispatch to idle compute units (from the top to bottom) to process it
CODE
A
B
C and D concurrently since the scheduler knows it is independent of each other
E
F and G concurrently since the scheduler knows it is independent of each other
H
I
This causes some of the compute units to be under occupied.
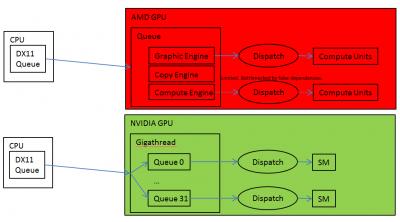
In DX12, there's now 3 types of hardware queue (graphic, compute, copy).
Step 1: The CPU will send the task to its respective queues (graphic task to graphic queue etc.) Remember, the task needs to be independent of each other so it doesn't rely on other data to process.
Now the queue becomes:
CODE
Graphic hardware queue: ABC
Compute hardware queue 0: DEF
Compute hardware queue 1: GHI
Step 2: The GPU scheduler will then dispatch to idle compute units (from top to bottom) to process it
CODE
A, D, G concurrently
B, E, H concurrently
C, F, I concurrently
This improves the utilization of the GPU since there is more work to feed the GPU.
On NVIDIAHowever, NVIDIA has a more intelligent to handle the work queue.
Again, we'll use the example from above. Stream ABC, DEF, GHI.
In DX11,
Step 1: the CPU will still submit the work queue sequentially.
CODE
DX11 CPU to GPU queue: ABC | DEF | GHI
Step 2: Once the GPU has received the task list, it will check for dependency and distribute to another hardware queue.
CODE
GMU to GPU Hardware queue 0: ABC
GMU to GPU Hardware queue 1: DEF
GMU to GPU Hardware queue 2: GHI
Step 3: The GPU scheduler will then dispatch to idle compute units (from top to bottom) to process it
CODE
A, D, G concurrently
B, E, H concurrently
C, F, I concurrently
This improves the utilization of the GPU since there is more work to feed the GPU.
However, in DX12 with "async compute" enabled,
Step 1: The CPU will send the task to its respective queues (graphic task to graphic queue etc.)
CODE
Graphic hardware queue: ABC
Compute hardware queue 0: DEF
Compute hardware queue 1: GHI
Step 2: NVIDIA driver now don't give a **** on the different hardware queues submitted from CPU. So it still uses its own scheduling method. As with DX11, once NVIDIA GPU has received the task list, it will check for dependency and distribute to another hardware queue.
CODE
GMU to GPU Hardware queue 0: ABC
GMU to GPU Hardware queue 1: DEF
GMU to GPU Hardware queue 2: GHI
Step 3: The GPU scheduler will then dispatch to idle compute units (from top to bottom)
CODE
A, D, G concurrently
B, E, H concurrently
C, F, I concurrently
SummaryFor NVIDIA, separate hardware queues from CPU to GPU doesn't do anything to improve its performance since it can already distribute work efficiently. If you're seeing slight performance drop when Async Compute is enabled, it is probably because of the redundant overhead created in Step 2 (check for dependency and distribute to another hardware queue). NVIDIA could probably do something to the scheduler so the GPU can skip this step and work similar to AMD's. But the performance gain is minimal, so NVIDIA prefer to work on other parts of the architecture to improve performance.
For AMD, separate hardware queues from CPU to GPU will improves its performance i.e. more works can be feed into the compute units.
In diagram:-
» Click to show Spoiler - click again to hide... «
DX11
DX12

» Click to show Spoiler - click again to hide... «
If you see AOTS performance, AMD's performance should be higher than NVIDIA due to its higher raw compute performance. As I mentioned earlier, Fury X best case (100% compute) could almost rival even GTX 1080 best case (100% compute). The problem is that games are not 100% compute performance. It depends on various things such as ROP, geometry hardware, memory bandwidth etc.
Finally in DX12, AMD GCN architecture is more efficient compared to Maxwell async compute capability. Why? Because it can assign work dynamically to the compute unit and the context switching of the CU is independent to draw-call.
Maxwell SMs can only do context switch during draw-call. If either the graphic stalls or the compute stalls (i.e. the SM cannot finish the allocate work in a single draw call), it will have to wait until the next draw call.
Pascal, however, doesn't require waiting for draw-call to do context switch. If any workload stalls, the GPU can dynamically allocate more processor to work on the task, independent of the draw-call timing.
So in summary, GCN, Maxwell and Pascal can still work on graphic and compute at a same time. It depends on whether the scheduler can dispatch work concurrently. NVIDIA GPU can fully dispatch work concurrently in DX11, but AMD GPU's ability to dispatch work concurrently is limited in DX11. However in DX12, it can fully dispatch work concurrently.
This post has been edited by Demonic Wrath: Jun 5 2016, 12:39 PM 

 Jun 4 2016, 10:34 AM
Jun 4 2016, 10:34 AM



 Quote
Quote



 0.0539sec
0.0539sec
 0.46
0.46
 7 queries
7 queries
 GZIP Disabled
GZIP Disabled