

 Apr 23 2020, 08:20 AM
Apr 23 2020, 08:20 AM

I have limited success. For example, reading this image will resulting in: THRAANKKYGOCDUVEEEEEEEERRFYMUOCCHR222Z55509GEBBUOCCKK

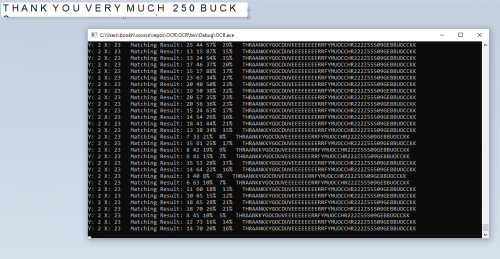
Input: THANK YOU VERY MUCH 250 BUCK
Output: THRAANKKYGOCDUVEEEEEEEERRFYMUOCCHR222Z55509GEBBUOCCKK
Because I scan the image (pixel by pixel) too close to each other, there are duplicate characters.
Moreover, some characters are identical to each other, such as 2 and Z, O and C.
What I did is very primitive form:
1. Get the font bitmap (A..Z, a..z, 0..9)
2. Read the input image
3. Convert it to B/W bitmap
4. Scan B/W bitmap and compare with font bitmap
But it is difficult even to recognize the font bitmap generated by the C# program itself. So far only able to recognize 55 chars out of 62 in total.
Limitation:
Input: Must have spacing between characters, only 18-point Arial font type allowed (depends on the constant value in C#)
Output: No punctuation, no whitespace , etc.
So, I am having fun creating the basic form of OCR. What do you know about the logic behind OCR? I know OCR is far more complex than I thought or what I have achieved now.
 Quote
Quote


 0.0159sec
0.0159sec
 0.42
0.42
 7 queries
7 queries
 GZIP Disabled
GZIP Disabled