QUOTE(UserU @ Dec 7 2013, 08:22 PM)
Btw, thanks for the helpful replies. Waiting for the sifu to explain

First let me start by stating that the reason you cannot understand why you are wrong and the reason why the people in the other forum cannot explain their answer to you is because everyone doesn't know how to define p-values and alpha-values properly in layman language and mathematical notation.
It is not necessary for you to understand it if you just want to use statistics as a business tool just like a pilot doesn't need to understand completely the workings of an airplane to fly it. In practice he just needs to know what happens when he uses the controls.
Now back to your questions. Let's starts with a simple "continuous probability distribution function"
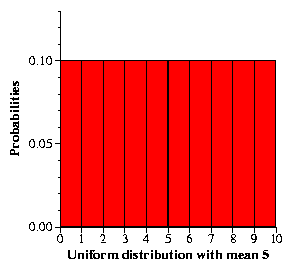
It's continuous in the sense any value between 0-10 is possible, ie. 5.6764567456.
If it was discrete, then only whole numbers 1,2,3,4 would be valid.
Now the probably of any exact value to occur is 0. That might seem counter-intuitive at first. But in statistic, a probability of 0 doesn't mean that the event cannot occur, it is just the lowest limit in the range of probabilities. The reasoning goes that there are really and infinite number of values between 0 and 10. You can write your decimals as long as you want. So to get a very exact values of say 4.454655762565 is very unlikely.
Hence a more practical way is to consider a 'range of events'. So we can say the the probability of getting more than 5 is 0.5 since the area between 5 and 10 covers 0.5 of the total area under the probability function line. So P(x>9) would be 0.1.
I hope this idea now comes intuitively to you. Now lets assume the graph above is the probability of closing stock prices tomorrow. And here is your situation.
Your investment strategy will result in a loss if the price of the stock closes above 9 tomorrow. And you will only use this strategy if there is a 5% chance it will failSo what would you do?
1. First see what is the probability of the price going above 9. Based on the graph it is .10
2. Determine is you are willing to take the risk. In this case no, since there is 10% chance of the price going above 9, hence a 10% chance of failure. But you already said you are only willing to take a 5% risk.
From the example above you can get a layman sense of p-values and alpha values.
Here 0.9 is the p-value for the an event/observation 9 or greater. Mathematically P(X>9)=0.1
And 0.05/5% is your alpha. Mathematically a=0.05
Graphically you can also see that 0.1 covers more area than your alpha.
We will come back to this later. Just keep all this in mind for now.
--------------------------------------------------------------------------------------------------------
Now lets put that example in hypothesis testings. That was an analog to 1-tail hypothesis test, since you only considered a case of values ranging out in one direction.
Typically hypothesis testing is used to determine the true statistic of the population when you only have data from a small sample. Say you're designing some stochastic model for a stock and you wanna determine if the probability of the price going up by 1 is 0.6. So you observe the stock for a month and you find that the price when up by 1 65% of the time. So in the long run, does the price of the stock really go up only 0.6 of the time?
Based on your standard deviation, you have determined that if the true probability is really 0.6, there is only a 1% chance that you will see a 0.65 probability or more this month you reject the null hypothesis of the prob being 0.6. Why did you reject it? Because sometime earlier you had arbitrarily decided that if you observed an
event that only happens 5% of the time or rarer, you will reject it.
In this sense P(X>0.65)= P(0.65<x<1) = 0.01 (Probabilities are limited to 1)(Recall here I'm talking a probability of a probability. It could be a probability of a mean, or probability or a range or a probability of anything. I'm purposely making this more complicated because I think you can handle it as you're a CFA candidate)
---------------------------------------------------------------------------------------------------------------
Now lets go to a two-tail test. A two tail test looks are probability of values ranging to the right and left of your null hypothesis. In the example above, you will be testing for any value above or below 0.6.
So if you observed 0.65, you will have to consider P(X>0.65) given that the true value is is 0.6, in other words P(X>0.65|H0 is true). And since it's a two tail test P(X<.065|H0 is true) Just like above P(X>0.65|H0 is true)=0.01 and obviously P(X<0.65|H0 is true)=1-0.01=0.99. Since the observed value is above the null value, the statistic you're obviously interested in is P(X>0.65|H0 is true)=0.01
Now here is where your misunderstanding begins. The p-value is defined as 2*min{ P(X>observed|H0 is true) is true);P(X<observed|H0 is true)} = 2*{P(X>0.65|H0 is true)=0.01} = 0.02
--------------------------------------------------------------------------------------------------------------
Statisticians knew that statistics would most likely be used by people who did not understand statistics nor cared to. So the devised a simple rule.
If p-value is more than alpha, then fail to reject null
If p-value is less than alpha, then reject null
And it is normally the statisticians providing the p-values and the decision makers providing the alpha as the alpha is basically the amount of risk one is willing to take in being wrong. So it made things simpler to have the p-value multiplied than the alpha being halved.
Recap,
1-tail test:
Events to the right of null, pvalue = P(X>observed|H0 is true)
Events to the left of null, pvalue = P(X<observed|H0 is true)
2-tail test
pvalue = 2*min{ P(X>observed|H0 is true) is true);P(X<observed|H0 is true)}
It doesn't matter what probability distributions you use. It can be normal or whatnot. The concept is the same.


 Dec 7 2013, 02:20 AM, updated 13y ago
Dec 7 2013, 02:20 AM, updated 13y ago



 Quote
Quote













 0.0295sec
0.0295sec
 0.48
0.48
 6 queries
6 queries
 GZIP Disabled
GZIP Disabled